
The Based Mindset of RISE: Rotating Gateways
TL;DR
- Based sequencing decentralizes RISE by having Ethereum validators (gateways) sequence L2 preconfirmations instead of a single sequencer.
- During The Aligning phase, multiple whitelisted gateways rotate in a round-robin order, each taking turns for a fixed sequencing window \(\mathtt{SW}\) measured in L1 blocks.
- Gateways register via a centralized Registry contract on L1, enabling deterministic on-chain discovery of the current and next sequencers.
- Efficient handover is achieved through real-time \(\mathtt{Shred}\) streaming and direct mempool synchronization between the current and next gateways.
- Liveness failures are detected after a maximum duration between commitments (\(\mathtt{D_{cm}}\)); if no new commitment arrives, the next gateway can trigger a rotation to maintain progress.
Introduction
Based sequencing is the decentralization strategy of RISE that aims to enhance security by leveraging the power of Ethereum. RISE, as a based rollup, works by having Ethereum’s validators sequence the rollup instead of relying on a single/centralized sequencer.
RISE’s Path to Based Sequencing
In the previous article, we laid out a three-phase path for RISE to approach based sequencing. In this path, The Aligning is the intermediate stop that transitions the current centralized RISE to a fully based system. That is, we aim to increase the number of gateways with permissions. Multiple gateways will be able to mediate the L1-secured preconfirmations with round-robin selection rather than a single gateway.
Why Round-Robin?
Round-robin (RR) is a simple yet efficient leader selection that can be used to ensure fairness. Unlike random leader selection, round-robin offers deterministic and predictable order of leadership. This in turn avoids bias or manipulation in leader selection.
- Simplicity. As this stage is not the final stop of RISE’s sequencing path, we do not think it is necessary to spend a lot of engineering time building better-designed mechanisms. Furthermore, in a world where performance matters the most, the simplicity of RR helps reduce the overhead and complexity of coordination compared to random leader selection methods.
- Fairness. Each participant gets an equal and chance to become the active sequencer, which helps prevent a single entity dominating the block building process. Since the order is fixed, adversaries cannot bias leader selection in their favor. As gateways are whitelisted, round-robin can enforce balanced participation without complicated randomness or leader election.
- Determinism. Based preconfirmations require the active/next preconfer to be determined ahead of time. Round-robin makes it simple to know who the next sequencer is, and thus, making request routing become more efficient.
Recall RISE’s Block Building Pipeline
RISE’s continuous block pipeline (CBP) is a highly-engineered pipeline that breaks down traditional block creation into smaller tasks. Transactions are processed immediately after landing to the sequencer’s mempool. Execution of the next block happens at the same with merkleization of the current block. This allows to allocate more time for execution, effectively increasing the execution throughput.
Furthermore, instead of building entire blocks all at once, RISE incrementally builds blocks in smaller segments called \(\mathtt{Shreds}\). Each \(\mathtt{Shred}\) serves as a batch of preconfirmations for transactions it includes.
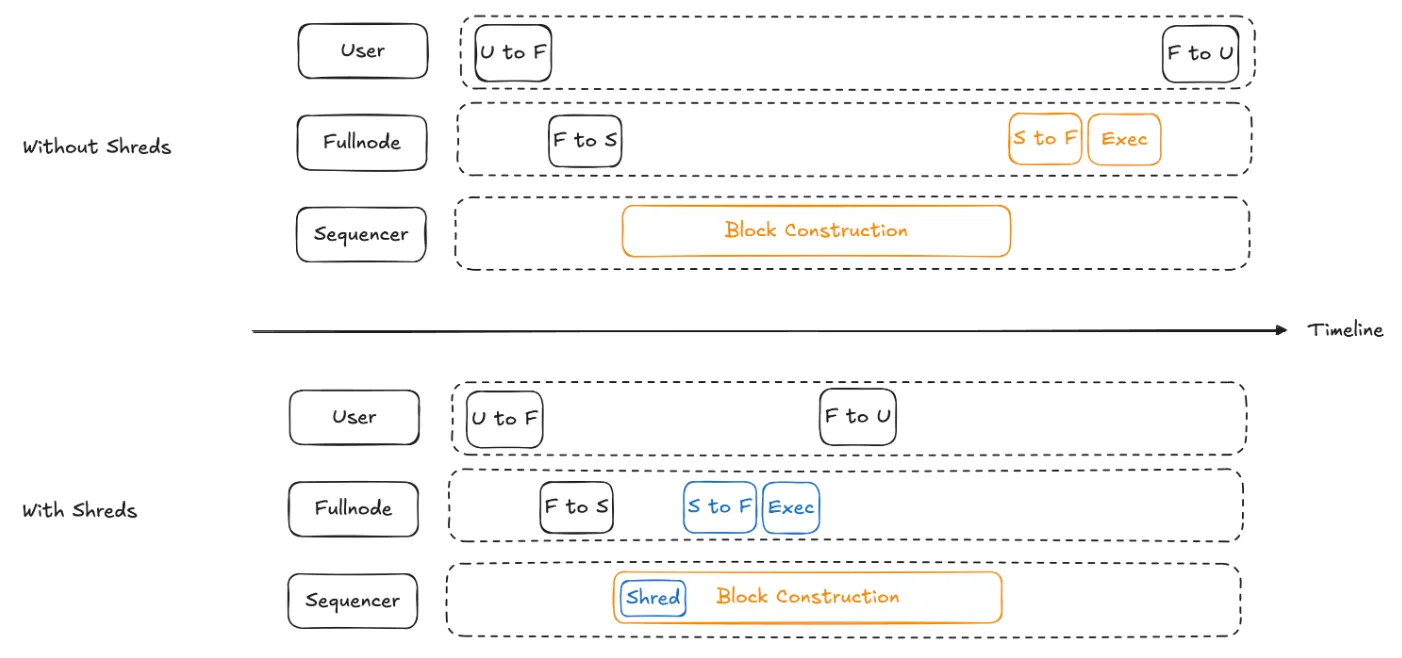
Block broadcasting is done per \(\mathtt{Shred}\) instead of waiting for the full L2 block, and a \(\mathtt{Shred}\) is just a few miliseconds long, allowing almost instant preconfirmations and fast state updates.
The Round-Robin Design
Notations
- The sequencing window \(\mathtt{SW}\). The duration during which each gateway takes turn to be the active sequencer. \(\mathtt{SW}\) is measured by the number of L1 blocks.
- \(\mathtt{D_{cm}}\). The maximum duration between two consecutive state commitments of the L2 to the L1. We assume that \(\mathtt{D_{cm}} \le \mathtt{SW}\), that is, each gateway MUST commit L2 states to the L1 at least once during its turn.
- \(\mathtt{GW}\) denotes a gateway, and can be subscripted when needed (e.g, \(\mathtt{GW}_i\)).
Gateway Registration and Discovery
At this phase, gateway registration is done in a centralized manner in which interested parties register to a RISE Council (managed by RISE) and RISE Council will manually whitelist gateways to the Registry contract living on the L1. The Registry contract implements the widely-adopted IRegistry interface to make sure it is extensible and compatible when we transition to the final phase.
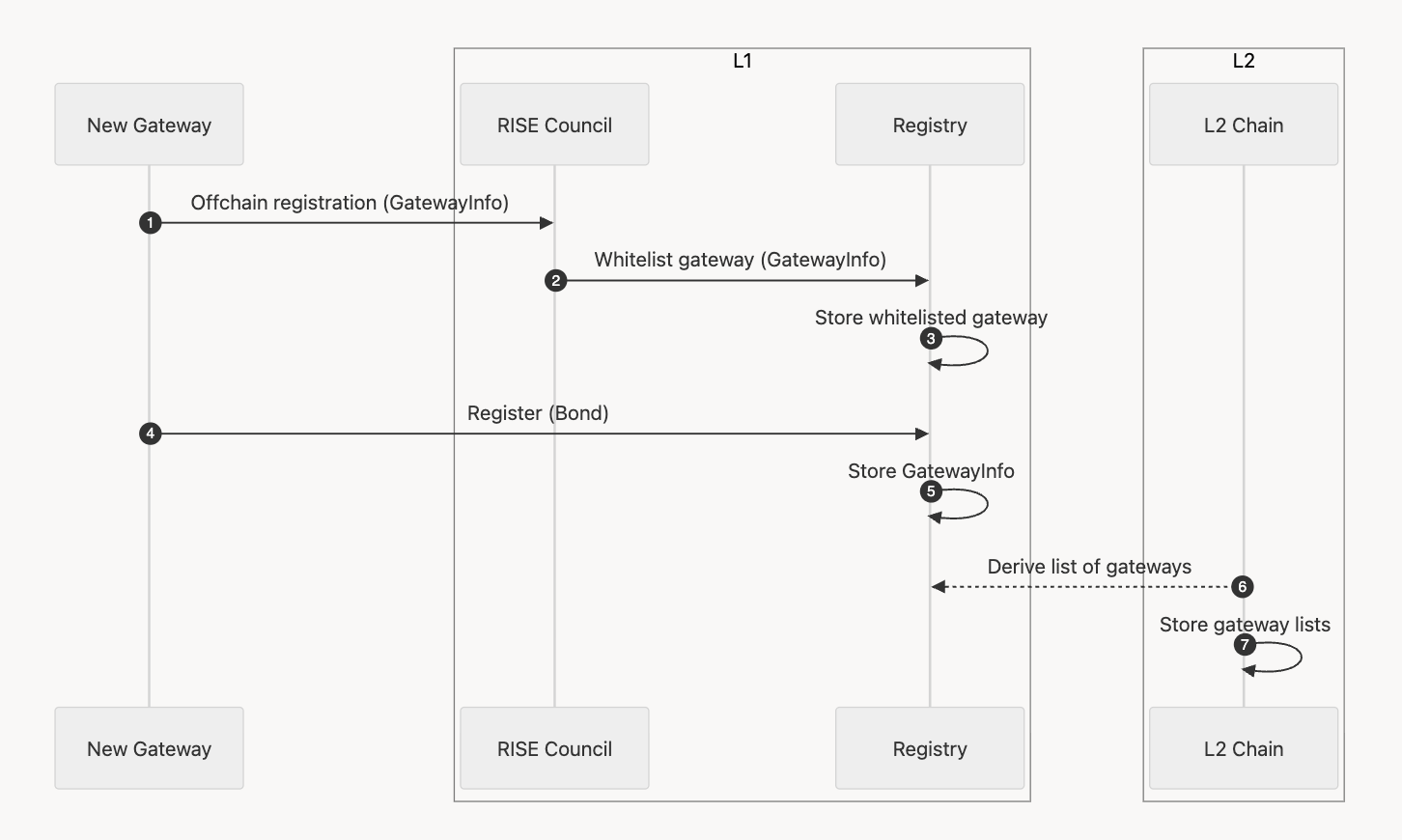
The L2 derives and keeps track of the list of gateways from the L1 when processing the chain. As the Registry contract lives on the L1 and is public, anyone knows about the current active gateway as well as the next gateway in the schedule.
Sequencing Window and Rotation Mechanism
The current gateway sequences the rollup in a period called the sequencing window (denoted by \(\mathtt{SW}\), and measured by the number of L1 blocks). Within the sequencing window, the current gateway has the exclusive right of transaction inclusion as well as ordering.
Gateway Lifecycle
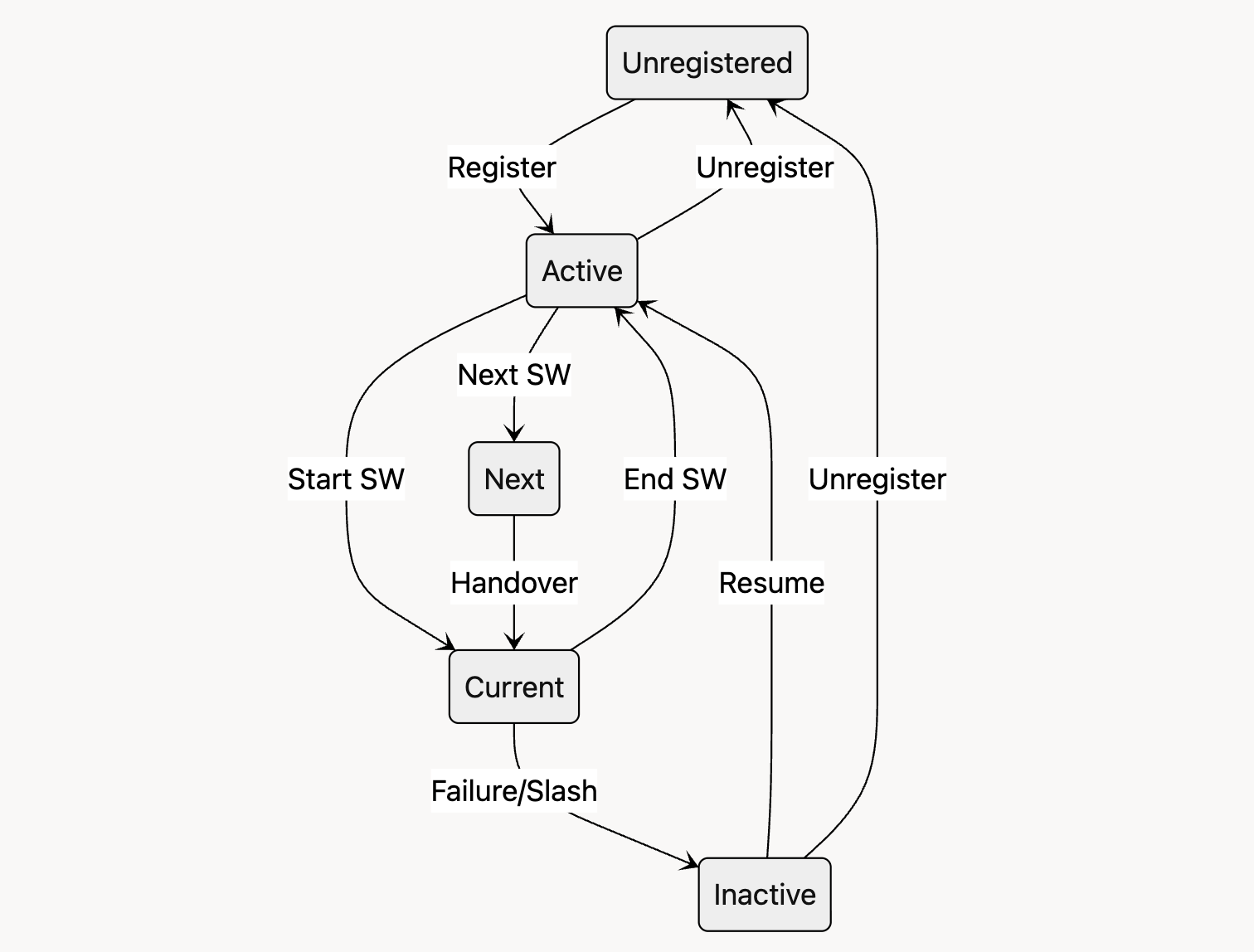
The lifecycle of a gateway starts with an entity registering to the Registry contract to become a gateway. This changes the state of the gateway from Unregistered to Active. Note that it is the responsibility of the gateway to fully sync the L1 and L2 networks before registration. An Active gateway becomes the Current/Next gateway if its current/next sequencing window arrives (see below). During the handover period, in which the current sequencing window ends, the Next gateway becomes the Current gateway while the Current gateway switches back to Active. If the Current gateway is offline or slashed (due to misbehaviors), it becomes Inactive and can only be Active again after resuming its role on the Registry contract (which requires adding more bonds). Active and Inactive gateways can unregister anytime to exit the gateway schedule.
Rotation Mechanism
From the gateway list information (i.e, \(\mathtt{GWList}\)) stored in the Registry, the L2 chain can always deterministically derive the current and the next gateways for a given L1 block (which eventually determines L2 epochs):
- Current gateway. \(\mathtt{curGW} = \mathtt{(l1.blocknum / SW)} \% \mathtt{GWList.len()}\).
- Next gateway. \(\mathtt{nextGW = curGW + 1}\).
Given these formulas, it is always possible for the rollup (as well as anyone else) to determine the current and the next gateways for efficient request routing.
Efficient Handover
To reduce any potential overhead during the handover period, it is essential that the current and the next gateways have consistent view over (1) the state of the network, and (2) mempool.
(1) is compulsory to guarantee the correctness of newly-created blocks built by the next gateway when its turn arrives. Fortunately, we already have an almost real-time synchronization mechanism, i.e, \(\mathtt{Shreds}\). \(\mathtt{Shreds}\) will eventually be slashable, therefore, the next gateway does not have to worry about the validity of received \(\mathtt{Shreds}\). (2) is needed (but optional) in the happy case to reduce the overhead during the handover period. With a consistent mempool view, the next gateway is able to pre-process transactions not processed by the current gateway.
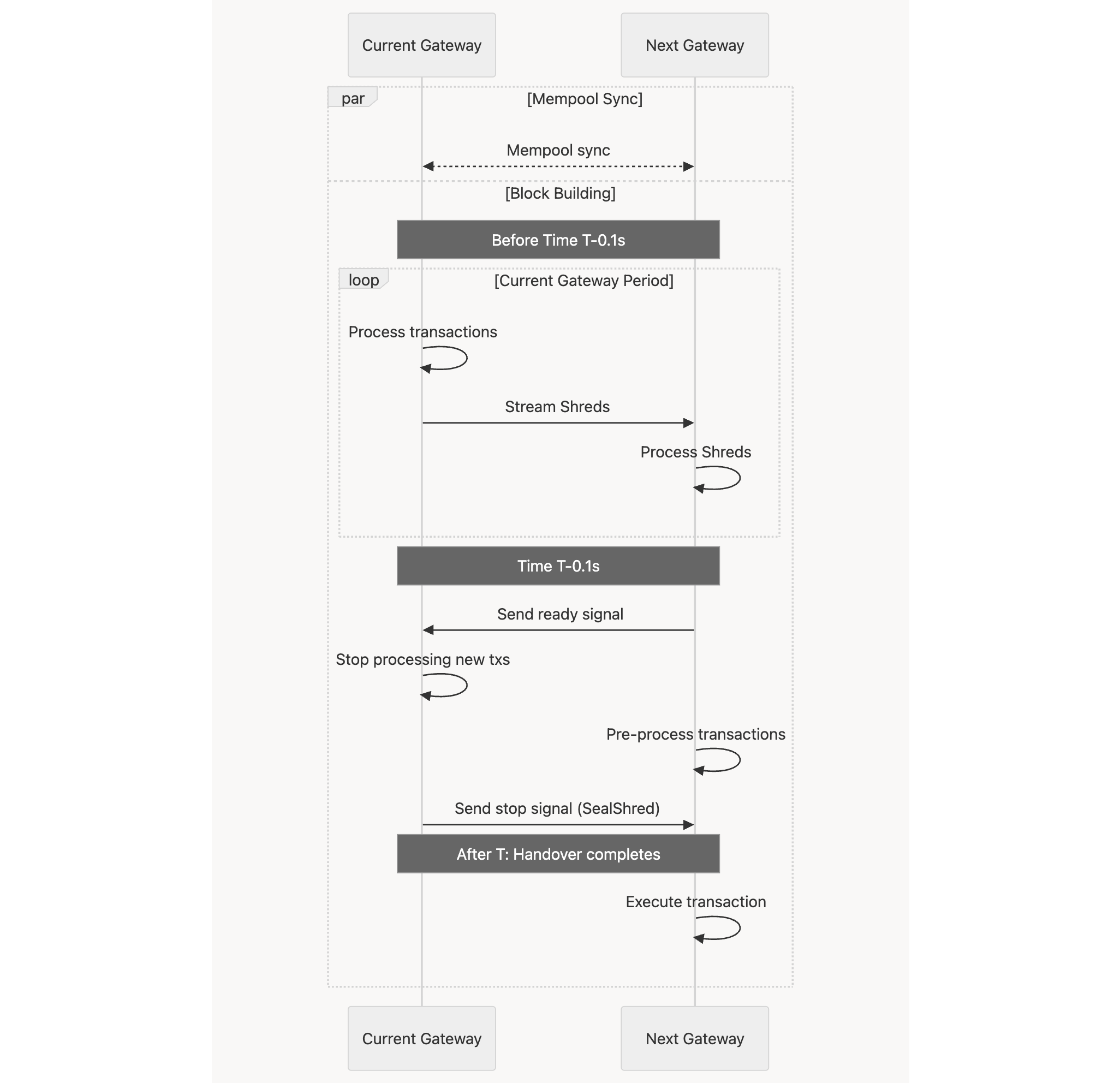
To efficiently facilitate these, we implement a direct communication channel between the current and the next gateways. This channel allows the gateways to have consistent mempool states, turning the next gateway to be a replica of the current gateway. With this direct channel, it is possible to efficiently perform the handover period.
As gateways are whitelisted, we assume they have some certain levels of credibility that they will not misbehave. Therefore, the design focuses on the happy case. In the worst case, pre-processed transactions are dropped if duplications are detected.
Liveness Failure Handling
So far, we have discussed the case where the current gateway is online and actively sequencing. What if the current gateway is offline and not producing blocks (i.e, liveness failure)? How to detect the gateway failure and progress the rollup?
One solution is to do nothing and just wait for the current sequencing window to end and the next gateway to step in. Parties wait until \(\mathtt{SW}\) L1 blocks have passed and the next gateway will takeover by the selection rule. However, as we also want the sequencing window to be sufficiently long enough (mainly to reduce handover overheads and maintain stable performance), waiting for the full sequencing window to end results in long liveness failure.
Observe that from the view of L1, it can only perceive that the current gateway is offline if \(\mathtt{D_{cm}}\) L1 blocks have passed and there is no new state commitment from the current gateway. Therefore, we can use \(\mathtt{D_{cm}}\) as the signal for gateway takeover.
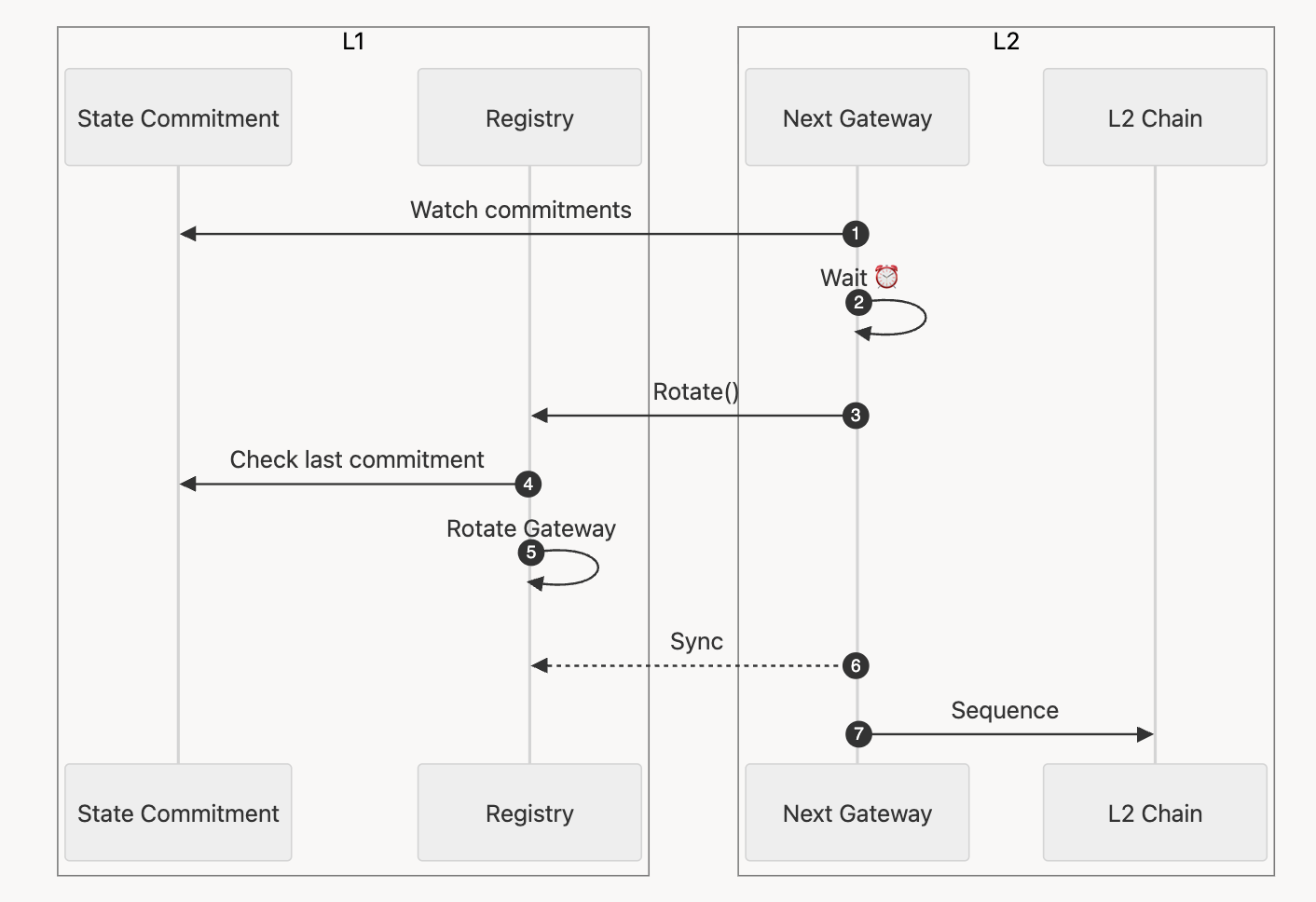
In this approach, if after \(\mathtt{D_{cm}}\) L1 blocks, no L2 state commitment is published to the L1 by the current gateway, the next gateway can signify the Registry and take over the active role. The Registry will check if the current gateway is indeed offline by querying the latest commitments and check if it passes \(\mathtt{D_{cm}}\). In this case, a proper value of \(\mathtt{D_{cm}}\) must be configured and set in the Registry contract.
- A small \(\mathtt{D_{cm}}\) results in more frequent state commitment ⇒ faster settlement, lower liveness risk but also higher operation costs for gateways.
- A large \(\mathtt{D_{cm}}\) results in a longer liveness failure.
Reusability
Although “The Aligning” serves as an intermediary step towards the fully based era, many components of the design can be reused/extended when we reach the final phase.
As the Registry contract implements the IRegistry interface, it can be upgraded to a new contract implementing the same interface while removing centralized components. L2 derivations or gateway discovery logics might stay untouched.
The synchronous communication between the current and the next sequencer can be reused to efficiently perform the handover task. In the case of gateway failure, a (default) fallback gateway can take over the role of the current gateway in the remaining of his sequencing window.
Conclusion & Future Works
The round-robin gateway rotation design balances decentralization, fairness, and performance during the transitional Aligning phase. This simple, deterministic rotation mechanism, combined with \(\mathtt{Shred}\)-based block building, ensures predictable leadership handovers and near-instant state updates while minimizing coordination overhead.
Looking ahead, the same Registry interface and communication protocols can be extended to a fully permissionless environment with the gateway lookahead determined by the L1 validator lookahead. Future works will explore more efficient failure detection mechanisms, gateway fallback for better liveness.